Logistic Regression 逻辑斯蒂回归
我们考虑用回归的方法解决分类的问题,如,对于一个顾客来说,买房和不买房取决于房屋的价格,我们记录多位用户买房的行为,可以得到房价和一个 0,1 二元结果的对应关系。
我们可以考虑用线性回归去拟合二元的结果,如:
y^=1,β0+β1x>0.5;0,β0+β1x≤0.5
事实上,逻辑斯蒂回归使用的是 sigmond 函数:
σ(z)=1+exp(−z)1
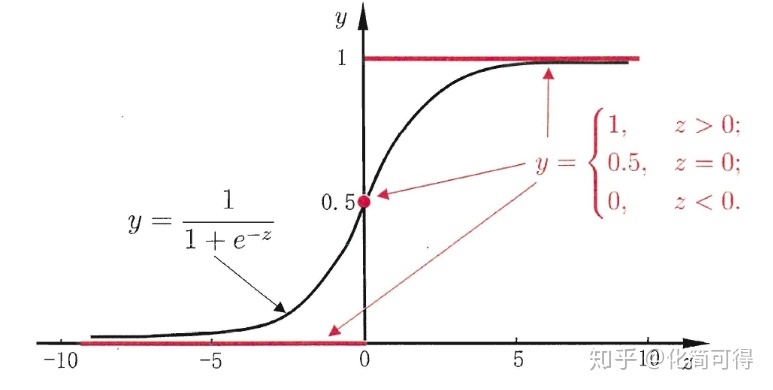
相对于上面的二元函数更加平滑,适合预测概率。
令 xiβ=β0+β1xi1+⋯+βpxip
于是,我们希望
P(y=1∣x,β)=σ(xβ)
定义似然函数
L(β)=i=1∏nP(yi∣xi,β)
也就是要这个 β 对应的概率最大。
取对数后,我们得到:
logL(β)=i=1∑n(yilogσ(xiβ)+(1−yi)log(1−σ(xiβ)))
我们定义损失函数:
J(β)=−logL(β)
因为我们希望对应概率尽量大,也就是负数尽量小。
梯度下降求解:
\frac{\part J(\beta)}{\part \beta_j} = \sum_{i=1}^n (\sigma(x_i\beta)-y_i) \times x_{ij}
因此,代码如下:
1
2
3
4
5
6
| for (int t=1;t<=iter;++t){
Matrix y_posi=sigmoid(X*beta.transpose());
long double cross_entropy=-mean(mul(Y,log(y_posi))+mul(flip(Y),log(flip(y_posi,1e-4))));
Matrix grad=(Y-y_posi).transpose()*X;
beta=beta+alpha*grad;
}
|
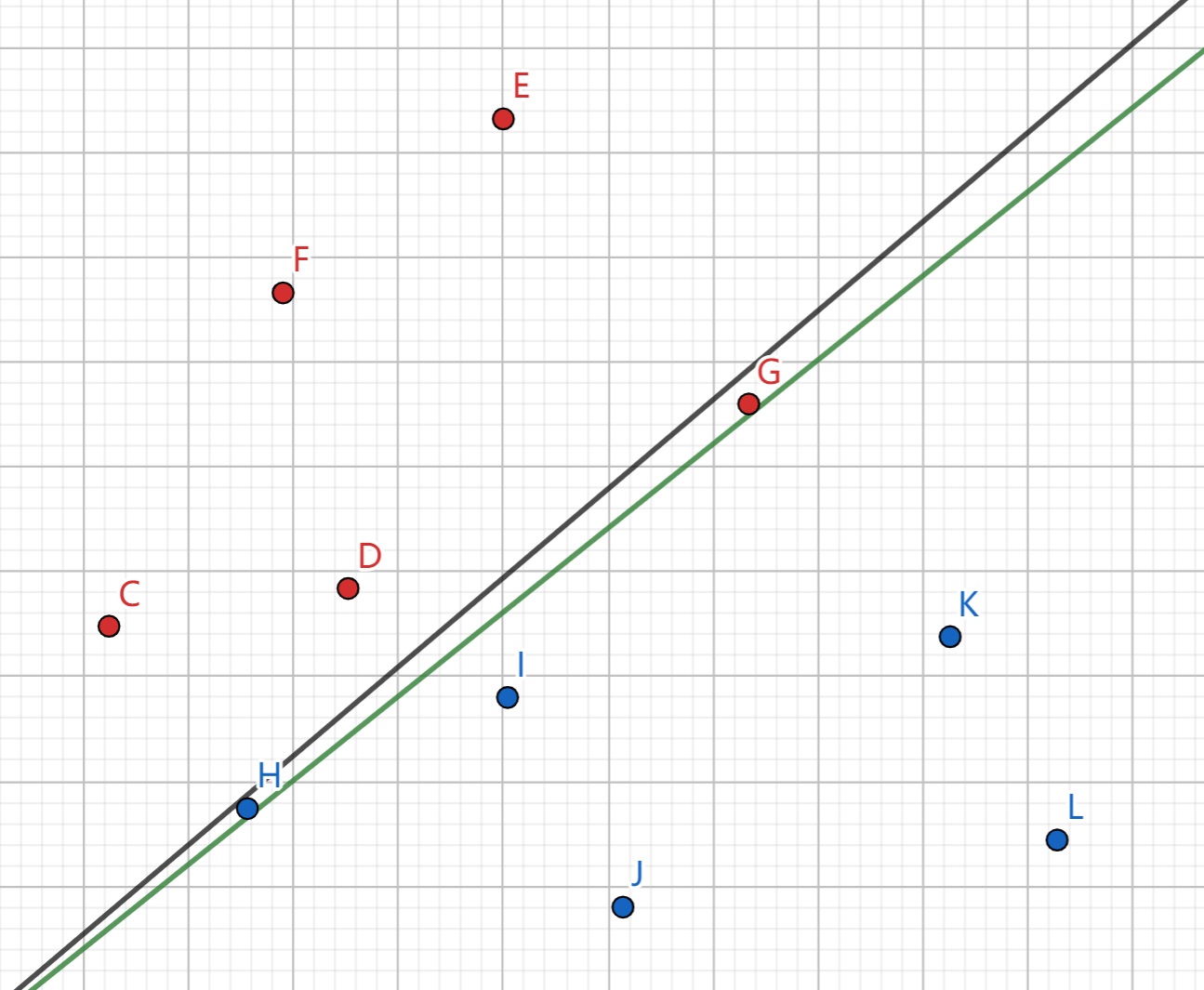
例如,利用 logistic 模型,我们就可以划一条直线,将两种不同颜色的数据点分开。
得出的 σ(xβ) 就是为红点的概率,如输出:
1
2
3
4
5
6
7
8
9
10
| 0.999999
0.998762
1
1
0.679219
0.62317
0.0232462
0
0
0
|
代表回归模型认为在 ABCD 四个点几乎能肯定是红点,IJKL 几乎是蓝点,但是不太好区分 HG 两个点。
而如果我们引入常数项,将每个点改写为 (1,坐标x,坐标y) 的形式,则可以发现能够非常好地匹配:
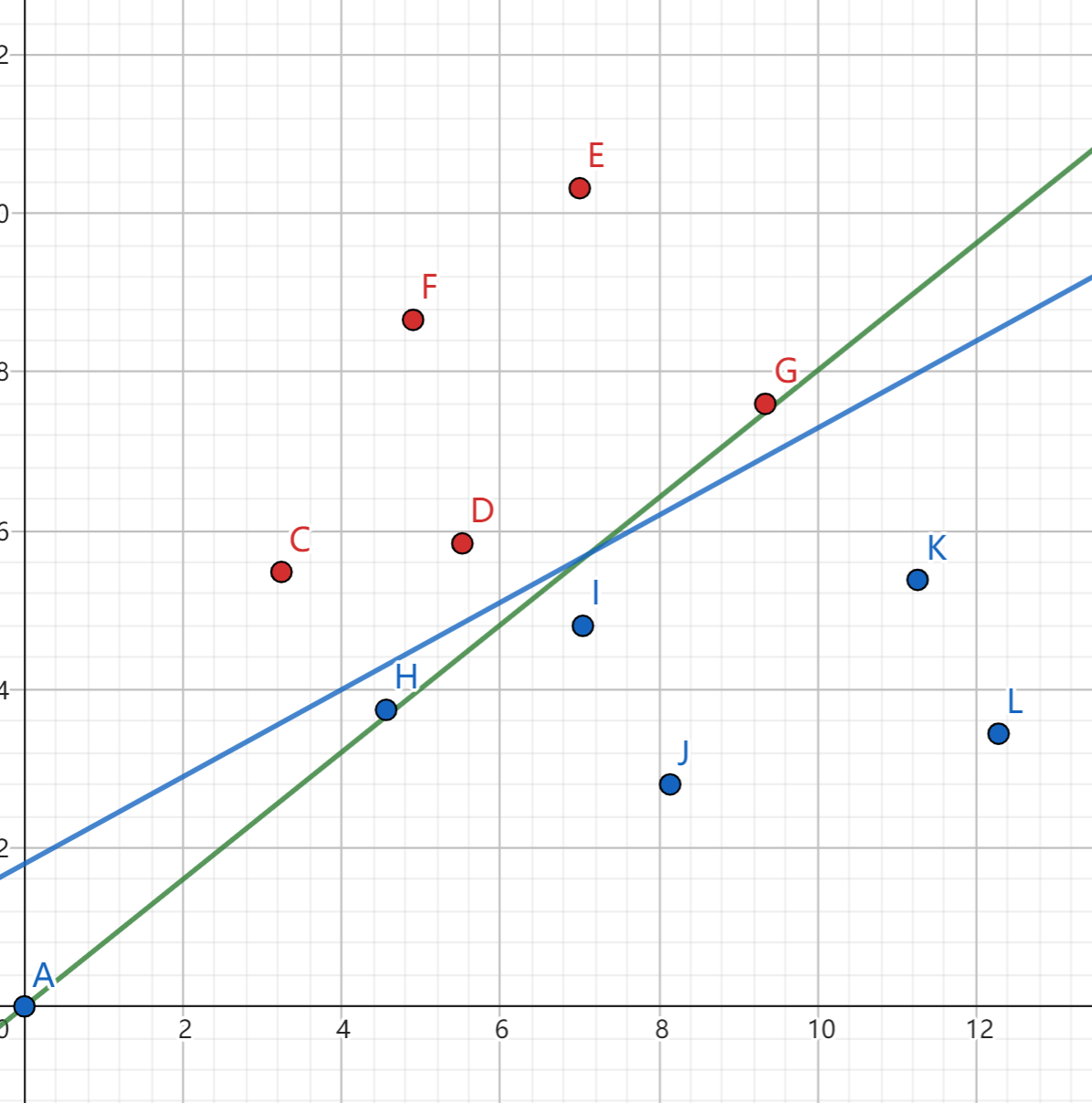
β 迭代完成为 -10.1665 -3.10623 5.6517。
则直线方程表示为 5.6517y−3.10623x−10.1665=0, 概率:
1
2
3
4
5
6
7
8
9
10
| 0.999978
0.996642
1
1
0.977559
0.0394075
0.00734588
0
0
0
|