启发式算法的定义
启发式算法 (Heuristic Algorithms) 是相对于最优算法提出的。一个问题的最优算法是指求得该问题每个实例的最优解. 启发式算法可以这样定义:一个基于直观或经验构造的算法,在可接受的花费 (指计算时间、占用空间等) 下给出待解决组合优化问题每一个实例的一个可行解,该可行解与最优解的偏离程度不一定事先可以预计。
在某些情况下,特别是实际问题中,最优算法的计算时间使人无法忍受或因问题的难度使其计算时间随问题规模的增加以指数速度增加,此时只能通过启发式算法求得问题的一个可行解。
利用启发式算法进行目标优化的一些优缺点如下:
| 优点 | 缺点 |
|---|---|
| 1. 算法简单直观,易于修改 2. 算法能够在可接受的时间内给出一个较优解 | 1. 不能保证为全局最优解 2. 算法不稳定,性能取决于具体问题和设计者经验 |
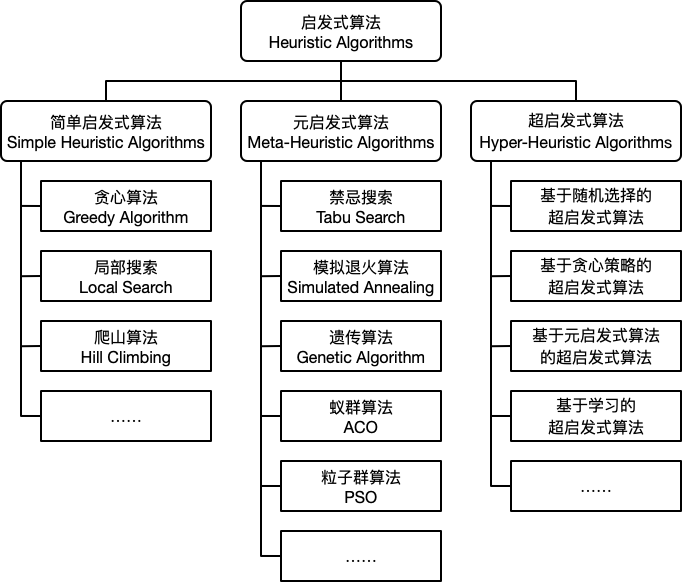
启发式算法简单的划分为如下三类:简单启发式算法 (Simple Heuristic Algorithms),元启发式算法 (Meta-Heuristic Algorithms) 和 超启发式算法 (Hyper-Heuristic Algorithms)。
启发式算法的引入——启发式合并
我们可以通过 的时间复杂度将 个元素合并到一个 个元素的集合之中,如果合并两个集合的时候,我们总是选择较小的集合合并到较大的集合,就会发现每个元素最多合并 次,其中 是集合总体的大小。因此,总体时间复杂度是 的。
这种算法其实是基于“直觉”的优化,却能取得较优的时间复杂度。
A star 算法
本质上也是基于直觉的优化,我们规定一个估价函数 ,每次优先更新比较优的方案。
求一个函数极值的方法
爬山算法
爬山算法是一种局部择优的方法,采用启发式方法,是对深度优先搜索的一种改进,它利用反馈信息帮助生成解的决策。
直白地讲,就是当目前无法直接到达最优解,但是可以判断两个解哪个更优的时候,根据一些反馈信息生成一个新的可能解。
因此,爬山算法每次在当前找到的最优方案 附近寻找一个新方案。如果这个新的解 更优,那么转移到 ,否则不变。
我们的重点在于最优方案的选择,需要满足:
- 最优方案在改变的方向。
- 如果当前方案已经是最优,新的最优方案一定和它重合。
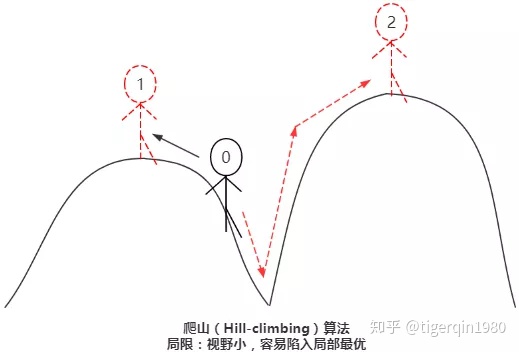
爬山算法的局限性在于会陷入局部最优解,不能到达全局最优解,为了解决这个问题,我们可以使用模拟退火和禁忌搜索。
模拟退火
根据 爬山算法 的过程,我们发现:对于一个当前最优解附近的非最优解,爬山算法直接舍去了这个解。而很多情况下,我们需要去接受这个非最优解从而跳出这个局部最优解,即为模拟退火算法。
过程:先用一句话概括:如果新状态的解更优则修改答案,否则以一定概率接受新状态。接受更劣新状态的概率随着时间推移减少,但也和新方案较劣程度 相关,较劣程度越小,转移概率越大,具体数学表达式为 。
例如:
1 | void simulateAnneal() { |
另外,模拟退火的初值选取也比较重要,这种类似于迭代的算法比较依赖于接近的初值。
对于几何空间中的分布,我们通常会选取初始点的算数平均。
模拟退火的初温设定也非常重要,我们可以:
- 均匀抽样,以方差为初温。
- 随机一组状态,确定最大目标值差 |\Delta_\max|,利用一定的函数确定初温。
- 根据经验公式给出。
禁忌搜索(TS)
和模拟退火一样,我们也想通过一种方法解决爬山算法易陷入局部最优解的难题。
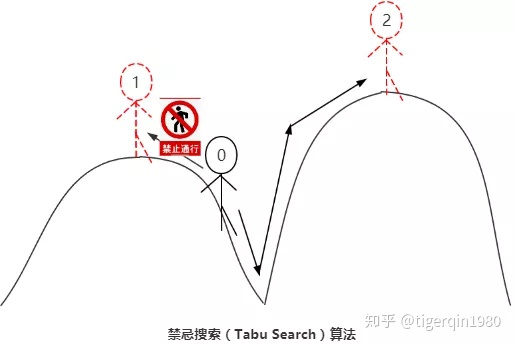
通过禁忌搜索,我们可以阻止再次访问之前的局部最优解。但是,由于我们的移动是连续的,需要一定的破禁准则,使得可以访问到所有的点。
一个基本的禁忌搜索算法的步骤描述如下:
- 给定一个初始可行解,将禁忌表设置为空。
- 选择候选集中的最优解,若其满足渴望水平,则更新渴望水平和当前解;否则选择未被禁忌的最优解。
- 更新禁忌表。
- 判断是否满足停止条件,如果满足,则停止算法;否则转至步骤 2。
Tabu Search主要构成要素
**(1)评价函数(Evaluation Function):**评价函数是用来评价邻域中的邻居、判断其优劣的衡量指标。大多数情况下,评价函数为目标函数。但自定义的形式也可存在,算法也可使用多个评价函数,以提高解的分散性(区分度)。
**(2)邻域移动(Move Operator):**邻域移动是进行解转移的关键,又称“算子”,影响整个算法的搜索速度。邻域移动需要根据不同的问题特点来自定义,而整个邻近解空间是由当前解通过定义的移动操作构筑的所有邻域解构成的集合。
**(3)禁忌表(Tabu Table):**禁忌表记录被禁止的变化,以防出现搜索循环、陷入局部最优。对其的设计中最关键的因素是禁忌对象(禁忌表限定的对象)和禁忌步长(对象的禁忌在多少次迭代后失效)。
禁忌表是禁忌搜索算法的核心,禁忌表的对象、步长及更新策略在很大程度上影响着搜索速度和解的质量。若禁忌对象不准确或者步长过小,算法避免陷入局部最优的能力会大打折扣;若禁忌表步长过大,搜索区域将会限制,好的解就可能被跳过。
**(4)邻居选择策略(Neighbor Selection Strategy):**选择最佳邻域移动的规则。目前最广泛采用的是“最好解优先策略”及“第一个改进解优先策略”。前者需比较所有邻域,耗时较久,但解的收敛更有效;后者在发现第一个改进解就进行转移,耗时较少,但收敛效率弱于前者,对于邻域解空间较大的问题往往比较适合。
**(5)破禁准则(Aspiration Criterion):**破禁准则是对于禁忌表的适度放松。当某个被禁忌的移动可得到优于未被禁忌的移动得到的最优邻域解和历史所得到的最优解时,算法应接受该移动,不受禁忌表的限制。
**(6)停止规则(Stop Criterion):**禁忌搜索中停止规则的设计多种多样,如最大迭代数、算法运行时间、给定数目的迭代内不能改进解或组合策略等等。
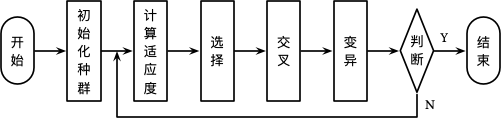
遗传算法
蚁群算法
粒子群算法
每个寻优的问题解都被想像成一只鸟,称为“粒子”。所有粒子都在一个D维空间进行搜索。
所有的粒子都由一个适应度函数(fitness function)确定适应值以判断目前的位置好坏。
每一个粒子必须赋予记忆功能,能记住所搜寻到的最佳位置。
每一个粒子还有一个速度以决定飞行的距离和方向。这个速度根据它本身的飞行经验以及同伴的飞行经验进行动态调整。
具体PSO算法如下: 维空间中,有个粒子
- 粒子位置:
- 粒子速度: 其中
- 粒子经历过的历史最好位置:
- 群体内(或领域内)所有粒子所经历过的最好位置:
- 一般来说,粒子的位置和速度都是在连续的实数空间内进行取值。
PSO公式:
:学习因子,一般为正数2
:取值范围[0, 1],是该区间均匀随机数
:粒子速度最大值
:表示相应变量
1 | double c1 = 2., c2 = 2., vmax = 2; //c1, c2为学习因子,一般取正数 |