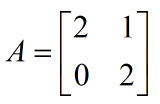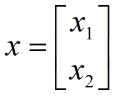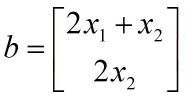矩阵乘法可以看做向量的重新组合。
我们有一组 n n n k k k k < n k <n k < n k k k
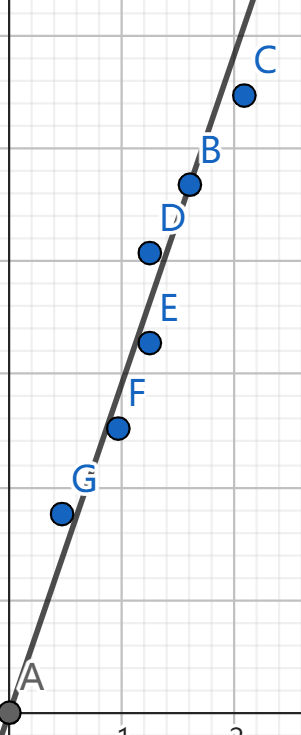
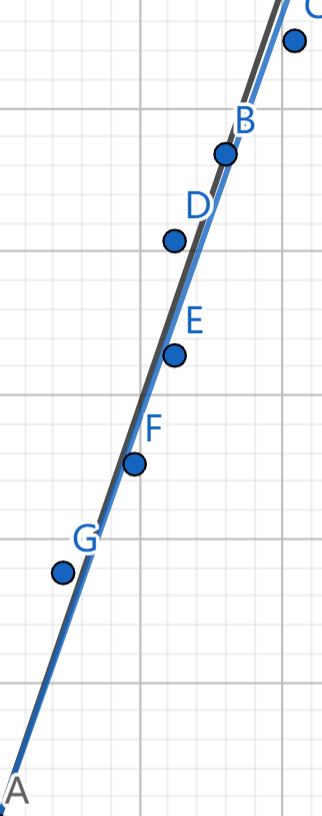
在一条直线附近,我们随便点 6 6 6 6 6 6 6 6 6 矩阵的对角化 。
我们构建:
A = 1 m ∑ i = 1 m v i v i T A=\frac{1}{m} \sum_{i=1}^m v_iv_i^T
A = m 1 i = 1 ∑ m v i v i T
可以看出,A A A v i v_i v i
这里,给出 6 6 6
1 2 3 4 5 6 1.6 4.68 2.08 5.47 1.24 4.07 1.24 3.28 0.96 2.52 0.47 1.76
我们求得 A A A
1 2 1.85068 5.20433 5.20433 14.7658
可见 A A A
接着,进行对角化,得到 Λ \Lambda Λ
于是,抹除第二个特征值,就将原数据拍平到了一维。对角化表示为
1 2 3 4 5 6 7 8 9 Q 0.332707 0.94303 Lambda 16.6019 Q^T 0.332707 0.94303
研究直线 0.332707 y = 0.94303 x 0.332707 y=0.94303x 0 . 3 3 2 7 0 7 y = 0 . 9 4 3 0 3 x
我们有一组数据,每列分别代表学生的数学、物理、英语成绩。
1 2 3 4 5 6 7 8 9 95 98 78 80 77 79 65 58 72 90 90 85 71 75 74 56 62 72 77 80 70 84 79 92 100 99 88
我们希望把数据压缩到二维,也就是找到一个平面尽量和原数据拟合。
首先计算 A A A
1 2 3 6545.78 6537 6362.67 6537 6545.33 6349.67 6362.67 6349.67 6278
数据进行对角化,舍去最后一个特征值,得到 V V V
1 2 0.582003 0.581606 0.568337 -0.313846 -0.484097 0.816793
研究两直线 0.582003x=0.581606y=0.568337z 、-0.313846x=-0.484097y=0.816793z 构成的平面,是
1 0.750182x-0.653746y-0.0992112z=0
于是,可以发现数学、物理成绩之间的相关性较高,可以用物理、英语成绩比较准确地预测数学成绩,如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 98 78 95.7175 77 79 77.5494 58 72 60.0661 90 85 89.6717 75 74 75.1452 62 72 63.5519 80 70 78.9735 79 92 81.0115 99 88 97.9115
最后,输入一个未知学生的物理、英语成绩,83 81,得到预测的数学成绩为 83.0425。
我们上面算法的本质是拿一个平面去拟合成绩,但是成绩数值较大,如果成绩在原点附近均匀分布就好了,于是我们想到可以将每一维减去平均值,这称为 中心化 :
S = 1 m − 1 ∑ i = 1 m ( v i − m e a n ) ( v i − m e a n ) T S=\frac{1}{m-1} \sum_{i=1}^m (v_i-mean)(v_i-mean)^T
S = m − 1 1 i = 1 ∑ m ( v i − m e a n ) ( v i − m e a n ) T
这里分母为 m − 1 m-1 m − 1
1 2 3 4 5 6 auto cov (std::vector<Matrix<Num> >v) v=to_mean (v); Matrix<Num>S (v[0 ].row,v[0 ].row); for (auto x:v) S=S+x*x.transpose (); return (Num (1 )/Num (v[0 ].row-1 ))*S; }
这生成了所谓的协方差矩阵,根据类似的操作,我们得到:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 98 78 94.6981 77 79 77.4924 58 72 58.3947 90 85 91.1 75 74 73.578 62 72 61.7571 80 70 75.9943 79 92 84.9801 99 88 100.005 83 81 83.4293
1 2 3 4 5 6 7 8 9 template <class Num>auto pca (std::vector<Matrix<Num> >v) auto S=cov (v); int n=S.row; auto p=diagonalize (S); auto V=p.first.transpose (); V.resize (n-1 ,n); return baseSolution (V).front (); }
可以发现,将 v v v X X X
C = X T X n − 1 C=\frac{X^TX}{n-1}
C = n − 1 X T X
而 X X X
C = V Σ U T U Σ V T n − 1 = V Σ 2 n − 1 V T C=\frac{V\Sigma U^TU \Sigma V^T}{n-1}=V\frac{\Sigma^2}{n-1}V^T
C = n − 1 V Σ U T U Σ V T = V n − 1 Σ 2 V T
这样,可以减少一部分计算量。
1 2 3 4 5 6 7 8 9 template <class Num>auto pca_with_svd (std::vector<Matrix<Num> >v) auto S=addH (to_mean (v)); int n=S.row; Matrix<Num>U,Sigma,V; std::tie (U,Sigma,V)=svd (S.transpose ()); V.resize (n-1 ,n); return baseSolution (V).front (); }
https://equationliu.github.io/2019-6-25-rmu/